
In Jamoma audio effects models it has been a long-standing issue how to ensure that the wet and dry signals are properly synced. This is important whenever we want to mix wet and dry.
One model where this has been an accute problem is the spectralGate~.model. This audio effect involves spectral filtering performed inside a pfft~ object. pfft~ introduce a delay, and according to its reference page, the delay “is equal to the window size minus the hop size (e.g., for a 1024-sample FFT window with an overlap factor of 4, the hop size is equal to 256, and the overall delay from input to output is 768 samples).”
With a window size of 4096 samples and a overlap factor of 4, our pfft~ object introduce a delay of 3072 samples. At 44.1 kHz sample rate that’s a whopping 70 milliseconds, more than enough to make a dry/wet mix utterly useless.
Today I found a simple way of addressing this. Before looking into the details, we should recap how audio gain, mixing, bypassing and muting are handled in audio models. Here’s a screenshot of the degrade~-model, our pet lab rat:
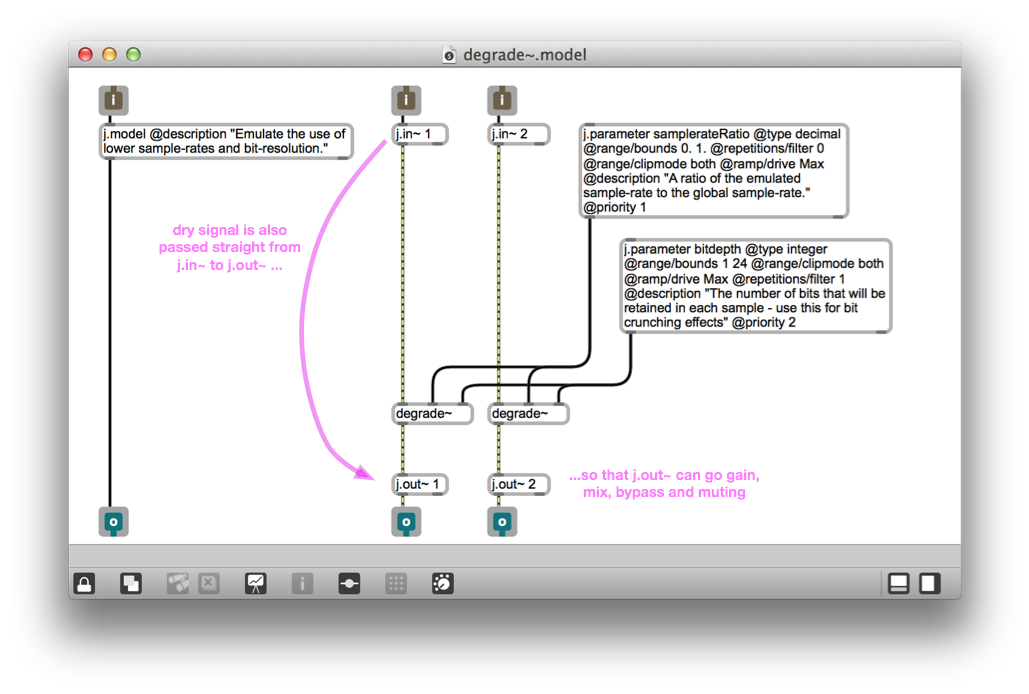
In terms of audio processing this is a pretty simple model. As you can see j.in~ and j-out~ objects have been added to the audio processing chain. In addition to audio signals passed along patch chords in the usual MSP way, the j.in~ and j.out~ objects also sets up a direct link, permitting j.in~ to pass audio directly to j.out~. This enables j.out~ to mix dry and wet signals, or bypass the wet signal altogether. j.out~ also controls model output gain level, as well as muting of the patch.
The trick then is quite simple: We just need to put j.in~ on a separate branch of the audio graph, and delay the signal reaching j.in~ order to compensate for the delay introduced by pfft~. This way the signals reaching j.in~ and j.out~ have the same amount of delay:

And finally, here’s a demo of what it sounds like. First we hear the dry signal, then the wet, and finally a mix of the two.